
Interpretability methods for neural networks are essential tools that help us understand and make sense of the complex decision-making processes within these black-box models. These techniques aim to provide insights into why a neural network makes specific predictions or classifications, shedding light on the inner workings of the model. By using various approaches, such as feature visualization, saliency maps, and attribution methods, interpretability methods help users grasp the relationships between input features and output predictions, making neural networks more transparent, accountable, and trustworthy.
In particular, as part of my PhD thesis I developed Transformational Measures to quantify the relationship between transformations of the inputs to neural networks and their outputs or intermediate representations in terms of invariance and same-equivariance.
Quantitative Evaluation of White & Black Box Interpretability Methods for Image Classification (2023)


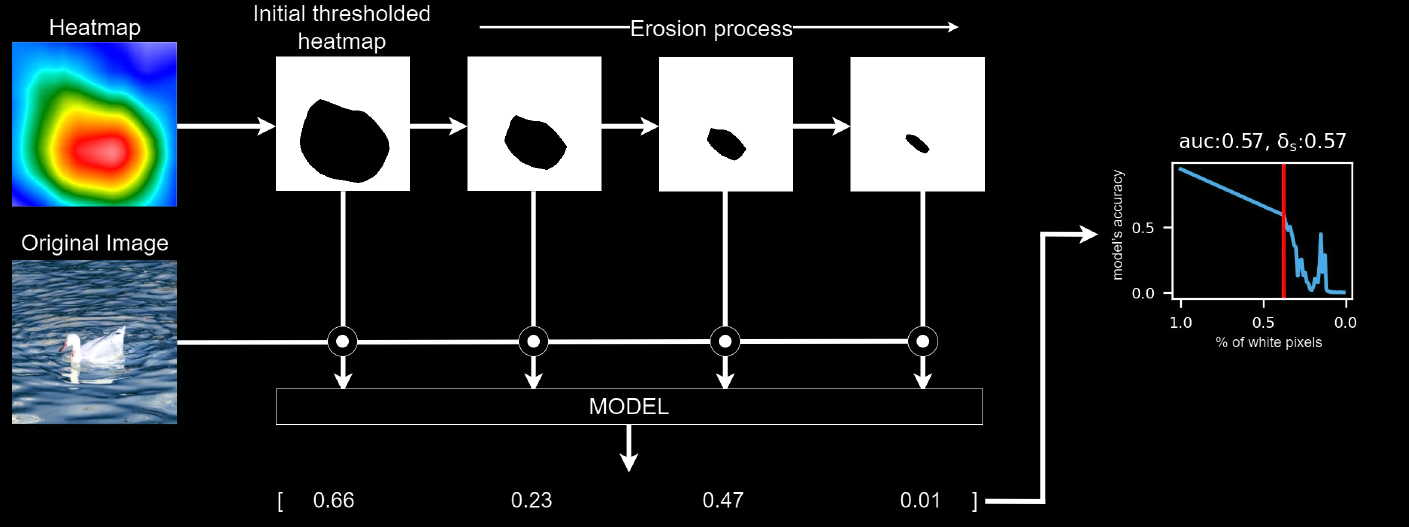
The field of interpretability in Deep Learning faces significant challenges due to the lack of standard metrics for systematically evaluating and comparing interpretability methods. The absence of quantifiable measures impedes practitioners ability to select the most suitable methods and models for their specific tasks. To address this issue, we propose the Pixel Erosion and Dilation Score, a novel metric designed to assess the robustness of model explanations. Our approach involves applying iterative erosion and dilation processes to heatmaps generated by various interpretability methods, thereby using them to hide and show the important regions of a image to the network, allowing for a coherent and interpretable evaluation of model decision-making processes. We conduct quantitative ablation tests using our metric on the ImageNet dataset with both VGG16 and ResNet18 models. The results reveal that our new measure provides a numerical and intuitive means for comparing interpretability methods and models, facilitating more informed decision-making for practitioner.






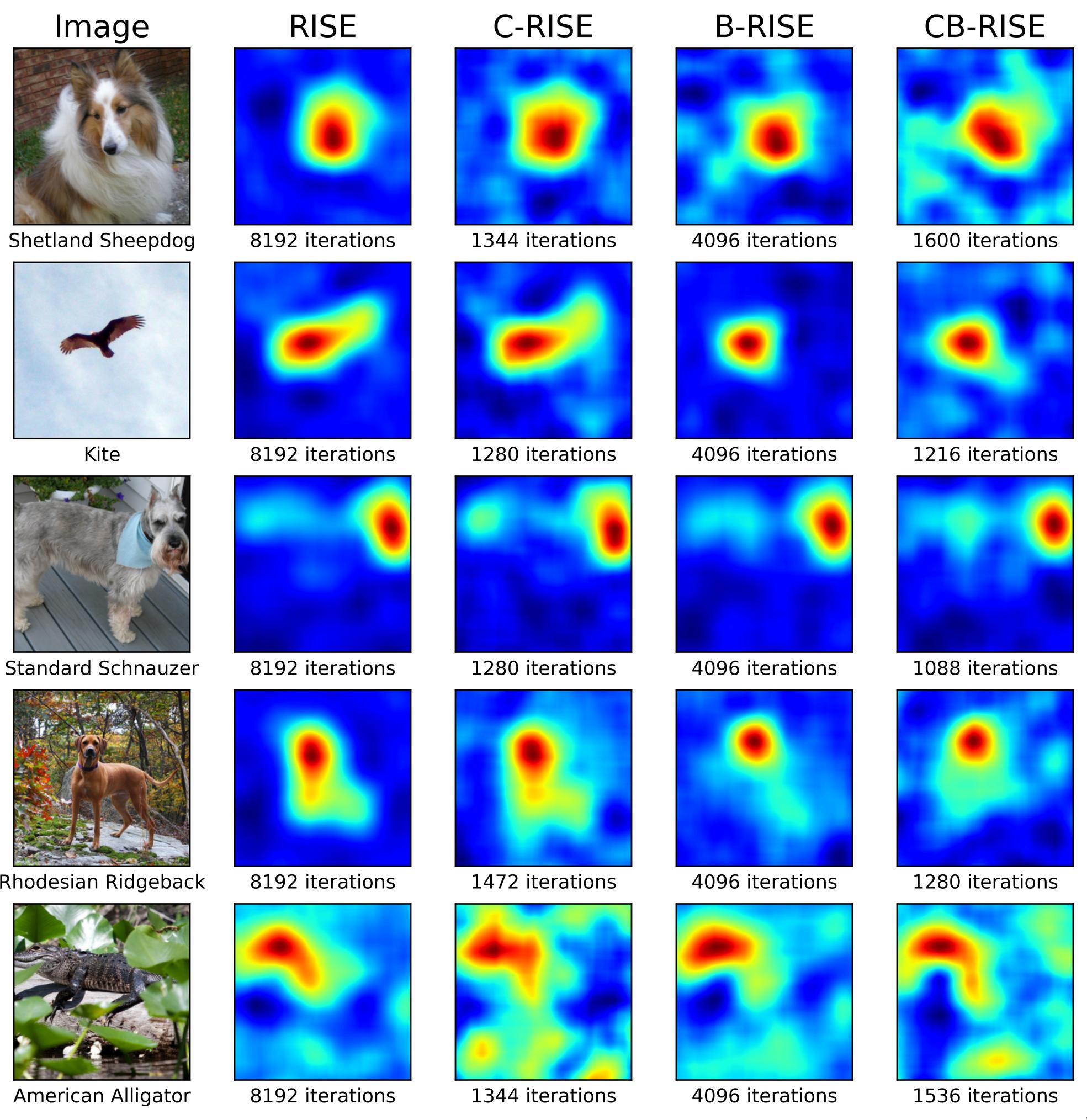
This paper presents significant advancements in the RISE (Randomized Input Sampling for Explanation) algorithm, a popular black-box interpretability method for image data. RISE’s main weakness lies on the large number of model evaluations required to produce the importance heatmap. Furthermore, RISE’s strategy of occluding image regions with black patches is not advisable, as it may lead to unexpected predictions. Therefore, we introduce two new versions of the algorithm, C-RISE and CB-RISE, each incorporating novel features to address the two major challenges of the original implementation. C-RISE introduces a convergence detection based on the Welford algorithm which reduces the computational burden of the algorithm by ceasing computations once the importance map stabilizes. CB-RISE, additionally, introduces the use of blurred masks as perturbations, equivalent to applying Gaussian noise, as opposed to black patches. This allows for a more nuanced representation of the model’s decision-making process. Our experimental results demonstrate the effectiveness of these improvements, successfully enhancing the effectiveness of the generated heatmaps while improving their quality, qualitatively, and showing a speedup of approximately 3.



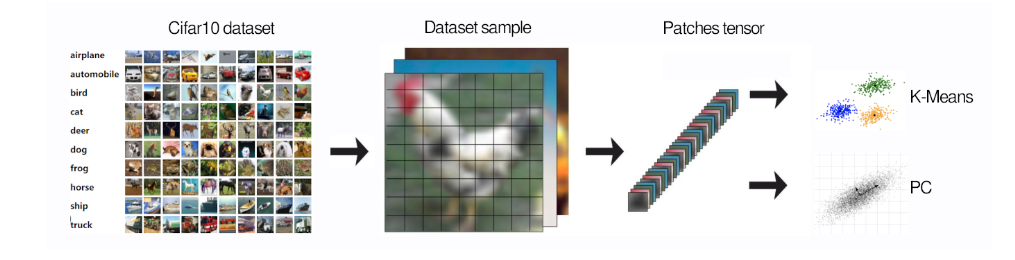
This paper presents an exploration of unsupervised methods for initializing and training filters in convolutional layers, aiming to reduce the dependency on labeled data and computational resources. We propose two unsupervised methods based on the distribution of input data and evaluate their performance against traditional Glorot Uniform initialization. By initializing solely the initial layer of a basic CNN network with one of our proposed methods, we attained a 0.78\% enhancement in final accuracy compared to traditional Glorot Uniform initialization. Our findings suggest that these unsupervised methods could serve as effective alternatives for filter initialization, potentially leading to more efficient training processes and a better understanding of CNNs.

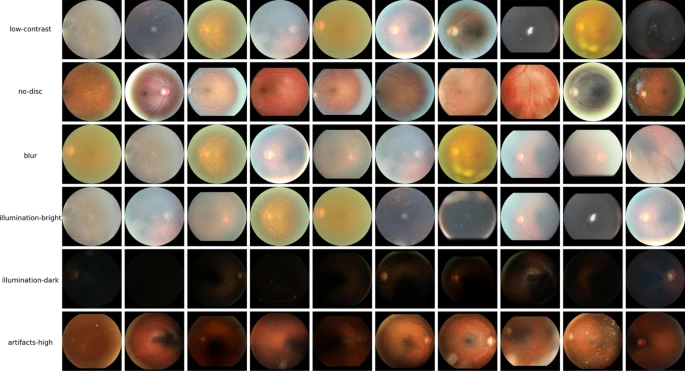
Consequently, this paper introduces a deep learning model tailored for fundus images that supports large images. Our division method centres on preserving the original image's high-resolution features while maintaining low computing and high accuracy. The proposed approach encompasses two fundamental components; an autoencoder model for input image reconstruction and image classification to classify the image quality based on the latent features extracted by the autoencoder, all performed at the original image size, without alteration, before reassembly for decoding networks. Through post hoc interpretability methods, we verified that our model focuses on key elements of fundus image quality. Additionally, an intrinsic interpretability module has been designed into the network that allows decomposing class scores into underlying concepts quality such as brightness or presence of anatomical structures. Experimental results in our model with EyeQ, a fundus image dataset with three categories (Good, Usable, and Rejected) demonstrate that our approach produces competitive outcomes compared to other deep learning-based methods with an overall accuracy of 0.9066, a precision of 0.8843, a recall of 0.8905, and an impressive F1-score of 0.8868.



Measures of invariance to transformations such as rotations, scaling and translation for Deep Neural Networks



TMEASURES: A library to compute easily compute Transformation Measures for PyTorch Models. Tensorflow version in progress. The library provides various invariance and same-equivariance measures ready to be applied to any neural network model. The library also allows to easily implement new transformational measures in a straightforward and efficient manner.


FGR-Net is a neural network trained to assess and interpret underlying fundus image quality by merging an autoencoder network with a classifier network.
