
Sign language Processing allows computers to recognize the sign of a specific sign language, and afterwards translate it to a written language.
In 2015, with Franco Ronchetti we recorded LSA16 and LSA64, the first sign language datasets for the Argentinian Sign Language (Lengua de Señas Argentina, LSA) focused on training Computer Vision models. Afterwards, we’ve also contributed new recognition methods, analysis and tools.


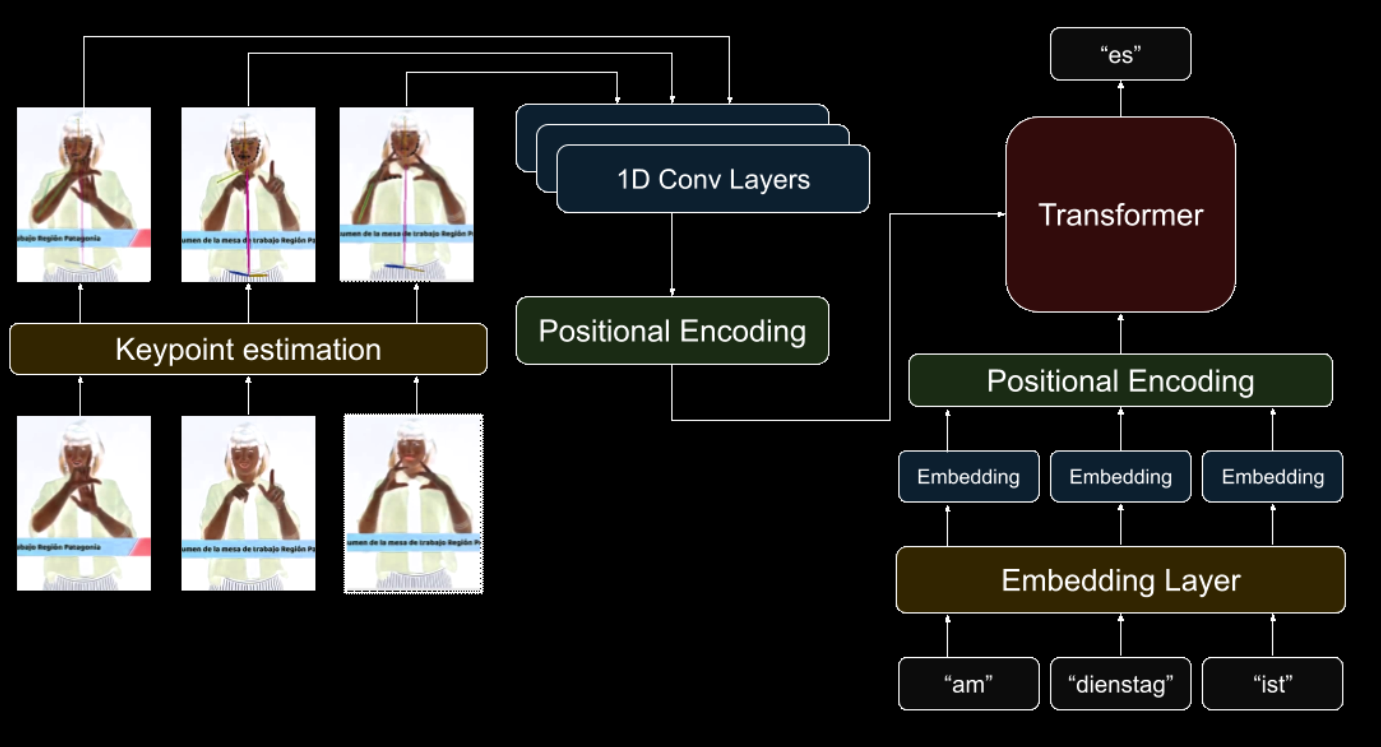
This paper presents the first comprehensive interpretability analysis of a Transformer-based Sign Language Translation (SLT) model, focusing on the translation from video-based Greek Sign Language to glosses and text. Leveraging the Greek Sign Language Dataset, we examine the attention mechanisms within the model to understand how it processes and aligns visual input with sequential glosses. Our analysis reveals that the model pays attention to clusters of frames rather than individual ones, with a diagonal alignment pattern emerging between poses and glosses, which becomes less distinct as the number of glosses increases. We also explore the relative contributions of cross-attention and self-attention at each decoding step, finding that the model initially relies on video frames but shifts its focus to previously predicted tokens as the translation progresses. This work contributes to a deeper understanding of SLT models, paving the way for the development of more transparent and reliable translation systems essential for real-world applications.






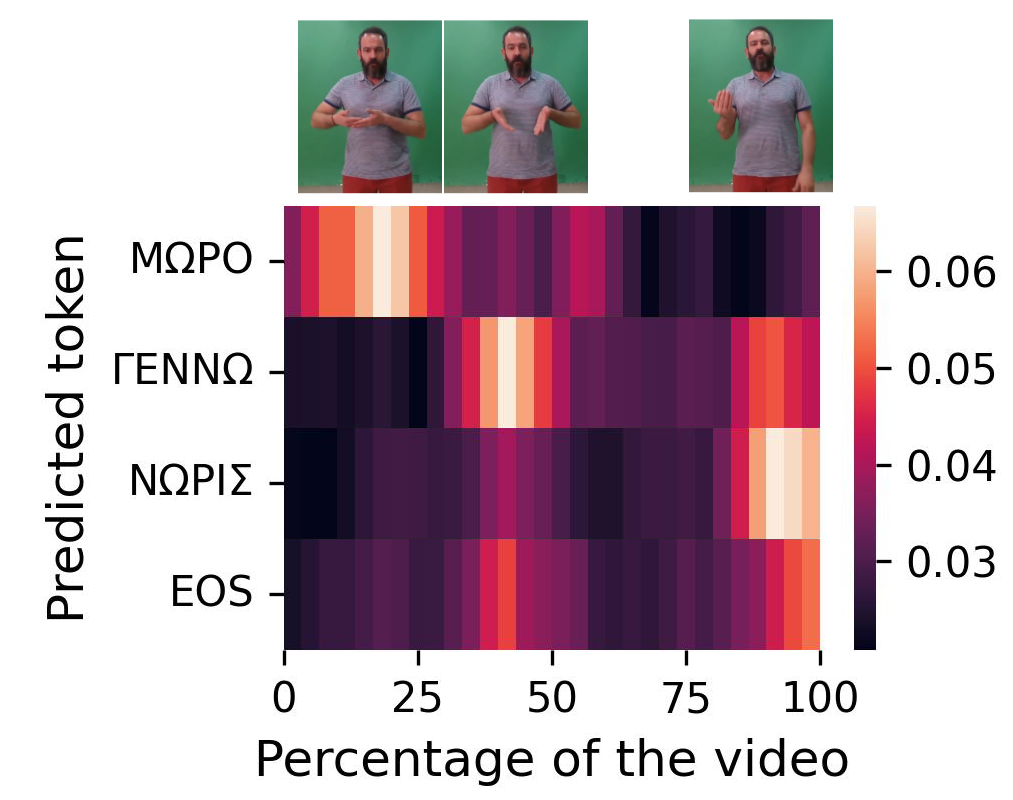
This paper presents the first comprehensive interpretability analysis of a Transformer-based Sign Language Translation (SLT) model, focusing on the translation from video-based Greek Sign Language to glosses and text. Leveraging the Greek Sign Language Dataset, we examine the attention mechanisms within the model to understand how it processes and aligns visual input with sequential glosses. Our analysis reveals that the model pays attention to clusters of frames rather than individual ones, with a diagonal alignment pattern emerging between poses and glosses, which becomes less distinct as the number of glosses increases. We also explore the relative contributions of cross-attention and self-attention at each decoding step, finding that the model initially relies on video frames but shifts its focus to previously predicted tokens as the translation progresses. This work contributes to a deeper understanding of SLT models, paving the way for the development of more transparent and reliable translation systems essential for real-world applications.


A sign dataset for the Argentinian Sign Language, created with the goal of training translation models. The dataset was captured from YouTube videos from the CNSordos channel.
Handshape datasets library (2020)


A single library to downloading and load handshape datasets. 10+ datasets supported



This database contains images of 16 handshapes of the Argentinian Sign Language (LSA), each performed 5 times by 10 different subjects, for a total of 800 images. The subjects wore color hand gloves and dark clothes.



A sign database for the Argentinian Sign Language, created with the goal of producing a dictionary for LSA and training an automatic sign recognizer, includes 3200 videos where 10 non-expert subjects executed 5 repetitions of 64 different types of signs.

A survey of the available sign language datasets, with information such as number of samples/classes, goal (continuous/isolated,dynamic/static), etc.

A descriptor based on a windowed distribution of action movements for action recognition. State of the art for MSRC12 and MSRAction3D when published.

The dataset contains 36 classes. The 36 classes consist of the arabic digits (0, 1, ..., 9) (10 classes) and latin/roman alphabet letters (a, b, ..., z) (26 classes). Recorded with Kinect, 3d hand trajectory data.